人工智能如何突破“黑箱”👨🏽🦲? ——對於大數據分析和資管行業的賦能

導語
以人工智能技術開發商業大數據,實現投資組合管理優化。

一直以來,科技進步都是推動資管行業發展的重要力量。隨著大數據等技術的發展👷♀️,人工智能時代離我們越來越近,新的科技也對傳統的投資組合管理方法提出了挑戰🪠。
過去70年,投資財富管理領域一直由諾貝爾經濟學獎得主哈裏·馬科維茨(Harry M. Markowitz)引領的均值-方差優化法(mean-variance optimization) 占主導地位。大數據時代,這一方法面臨明顯的瓶頸。
這一傳統方法要求投資者首先對資產回報的分布進行估算,再根據風險收益偏好和操作便捷程度進行決策。由於第一步估算存在嚴重偏差🔯,且無法系統性地考慮到投資者動態資金局限和交易成本等因素,該方法一直為人所詬病🪶。同時🫔,現代金融數據具有高維度🏑⭕️、高噪聲、非線性等特點,傳統計量經濟學手段對於數據中的信息提取十分有限,很難把握其中的非平穩動態和復雜的交互作用。不過,現在AlphaGo、Siri等人工智能中的深度神經網絡強化學習模型可以有效解決這些問題,大數據和人工智能技術的發展為投資財富管理決策提供了新的思路和前景🎏。
當前,大數據以前所未有的數量、維度和頻率噴薄而出,並且在大量決策場景中以傳統數據源(如調查或財務報告)的替代補充形式出現。這些原始數據具有復雜且不規律的結構(如衛星圖片、語音和視頻、文本🍯、移動足跡等)。與此同時🙂↔️,機器學習與人工智能算法作為大數據分析方法大量湧現。隨著大數據與人工智能迅速滲透到社會生活的各個層面,傳統上依靠人為判斷的決策受到深刻影響👨🏽🦲,如雇用決定、貸款贈款、刑事判決、財務建議等⏬。
數據生成方式和“黑箱”問題限製AI賦能金融
雖然科技的發展催生了大量的數據👏🏻,但社會科學中的數據生成過程不同於自然科學中的數據生成。雖然高維和非線性的金融數據與科學和工程學中的大數據高度相似,但與科學數據相比,業務或財務數據往往具有更低的信噪比和更高的稀疏性🧚🏽♀️,並伴有較多內生變量之間的交互作用🤷。
與此同時,我們必須認識到👩🏿🎨,與人體基因序列或自然科學原理不同,商業環境和市場在快速發展、高頻演變,政策也隨之不斷變化🧗♂️,代際之間的行為也不盡相同⁉️。我們不能將現有的機器學習軟件包和大數據分析盲目地投入對經濟和金融問題分析的應用。經濟大數據和機器學習的現有應用只能為模型的取信和調整提供有限的參考,許多方法必須在了解商業和經濟學原理的基礎上進行改良🌔🌀。
與此同時,基於大數據的人工智能算法經常被描述成一個無人理解的“黑箱”🏌🏽♂️,人工智能算法的可解釋性問題時常被提起。盡管數據處理技術不斷更新迭代,但人工智能和大數據分析對歷史數據仍存在嚴重依賴🧜🏽♂️。同時,大數據和人工智能模型往往對特別對象,尤其是經驗上處於不利地位的對象產生相當偏見(見表1)。
表1 知名人工智能系統的內在偏見
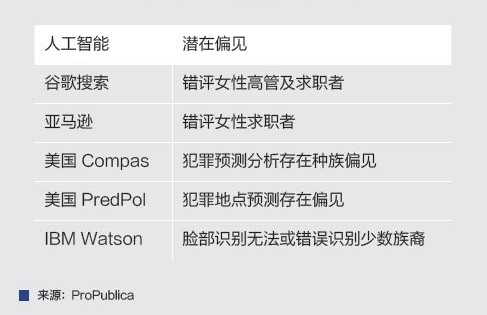
例如🚵,在圖片識別模型的構建過程中🚨,研究者需要對大量的圖形文件手動標記並歸類。在一些人臉識別系統的訓練過程中,由於少數族裔的圖片數據缺失,研究者發現模型可以正確識別近99%的白人測試者的性別,卻只能正確識別65%的黑人測試者📠。這樣的誤差證明了人工智能的設計過程仍存在諸多問題和缺陷⛺️。
在更嚴肅的應用場景中,人工智能的潛在偏見可能造成嚴重後果。在美國多州司法裁判中廣泛使用的人工智能Compas系統體現了這類偏見的危害性。在判決及量刑過程中👩🏿💼,Compas系統會根據嫌疑人對一系列問題的回答估計嫌疑人的“再犯率”。在一些判決中,Compas對有三次持械搶劫犯罪史的白人盜竊犯打出了3分(較低可能再犯)🏋🏽🤸🏿♀️,而對僅有四次未成年輕罪的黑人盜竊犯打出了8分(極有可能再犯)💆🏻🧊。由於Compas系統算法及邏輯並未公開,該系統的使用雖然一定程度上提高了司法速度,但是仍然造成了許多誤判,並在美國法律界引起了爭議。
人們通常將偏見問題歸因於人工智能的訓練數據。然而算法設計人員對人工智能的校正以及人工智能的反饋很有可能加劇使用者的偏見。這樣的可能性並未引起模型設計者足夠的重視。從數據收集到理論假設🚨,人工智能模型往往包含了大量由歷史偏見、隨機錯誤和意識形態造成的偏差。模型還可能迎合用戶的沉迷和偏執而誘發不當行為👸🏼。
解決此類問題首先要了解各種機器學習模型的經濟學原理。然而,大部分相關模型具有顯著的“黑箱”特性🤷🏼,對於模型的因果關系及經濟學原理釋義仍十分有限。這也影響了機器學習在經濟👮🏼、金融等社會科學應用中的推廣🏄♂️。
“強化學習”優化投資組合
強化學習(Reinforcement Learning)是人工智能領域的重要分支👨👨👧👧。在強化學習中🧜🏽♀️,施教者通過設定策略網絡來對模型根據環境做出的行動提供獎懲信息,以達到強化訓練的目標。強化學習在計算機視覺、語音識別、自動駕駛等領域已經獲得了廣泛的應用。而在社會科學領域中🤷♀️,相較於已經被廣泛研究的監督學習和無監督學習,強化學習的應用仍處於起步階段。
強化學習在投資組合優化問題上有很強的應用性。強化學習擅長解決投資組合優化問題包含的諸多隨機決策🚵🏿♀️。通過調整獎懲機製和績效函數,強化學習可以精準解決投資者的不同需求,如對高夏普比率進行獎勵並對過度借貸策略進行懲罰。與其他專註於提高收益的算法相比,強化學習算法具有更高的靈活性和針對性。在Cong等2019年和2020年連續推出的論文[1]中, 作者們通過一系列先進的人工智能技術對強化深度學習的金融應用進行發掘,發明了AlphaPortfolio人工智能和序列學習等投資模型。
一方面,基於跨資產神經網絡及註意力機製提高了參數準確度🔴。AlphaPortfolio的模型使用了600余個資產信息作為輸入參數🤟🏼,其中包括股指回報率👩🏻⚖️、資產收益率、買賣價差等。在此基礎上,作者們將多個不同資產輸入神經網絡(圖1)⚙️。模型將根據策略機製和輸入參數為所有相關資產打分。所生成的投資組合將重倉高分資產,同時空倉低分資產。通過模型,AlphaPortfolio生成的投資組合確保了較高的收益和較低的波動,並在各種經濟條件限製下維持高於2.0的夏普比率。
其中,註意力機製(Attention Mechanism)就被作者們加以改良為擴資產註意力網絡(Cross-asset Attention Network)👩🦱。在翻譯長句中的某一單詞時,一般的模型會賦予長句中所有單詞相同的權重,然而,目標單詞本身理應獲取較句中其他詞語更高的權重。在投資組合模型的應用中,註意力機製使我們對資產的評分更專註於單一資產本身的參數,減輕了組合中其他資產對評分公允性的影響。
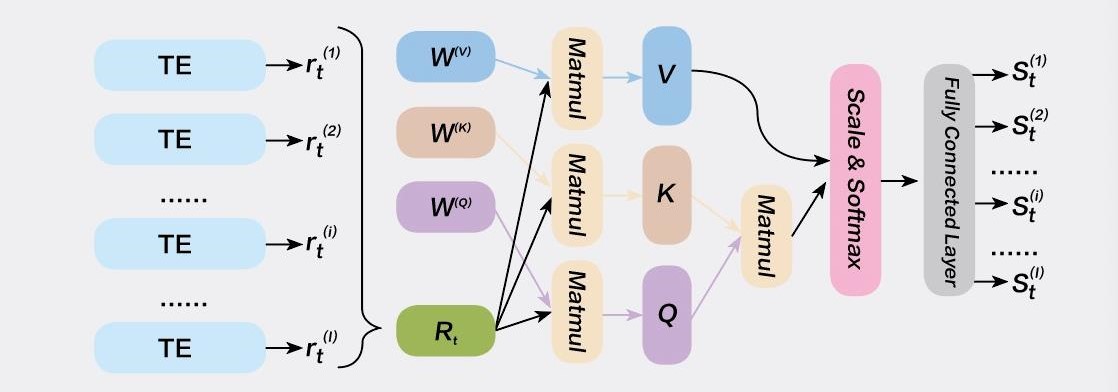
圖1 神經網絡模型
另一方面,通過多項式敏感度可以分析解讀模型的經濟學意義。由於機器學習與神經網絡模型通常具有較高維度和非線性等特點,使用者往往在理解模型背後的經濟意義時遭遇困難👩🎤。而多項式敏感度分析可以將高維度的非線性模型投影到多項式模型上,並逐一分析資產參數對模型評分的貢獻度(見圖2)👩🏿✈️。結果顯示🤘🏿,庫存、稅前利潤率、現金資產率等參數對評分具有較顯著的作用。這些結果與其他投資研究的成果一致,並對模型的參數選擇提供了重要參考。
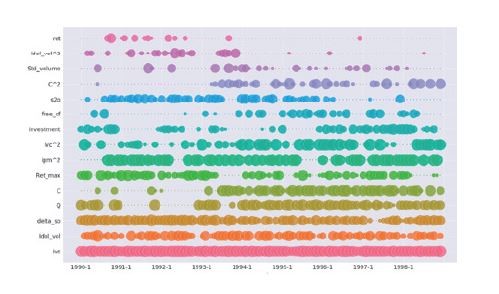
圖2 參數貢獻度演化(1990—1998年)
文本因子 “對話”人工智能
與數值數據不同👩🏻🎓,文本數據由自然語言組成,因此也具有比數值數據更優越的可解釋性🟫。通過自然語言處理算法🦹🏼,我們可以更好地理解人工智能機器學習模型,找到其潛在的主題及邏輯(見圖3)🤽🏽。Cong等(2018)[2]所開發的文本因子體系便提供了一種有效的利用文本空間解讀大數據人工智能應用的途徑🤹🏻♀️,也是AlphaPortfolio所采用的一種經濟解讀。
從上市公司的季報或年報文檔以及財報會議記錄出發🙇🏻♂️,自然語言處理算法先將原始文本轉換成數值向量,再將數值向量進行聚類,最終,在各個聚類上建立文本因子🧘🏻♂️。這種以數據驅動的分析模式可以拆分復雜的語言結構,並且確保使用者有能力解釋人工智能模型產生的結果🗑,並將模型應用於不同行業、不同背景的上市公司。在上文所述的模型中,在季報與年報中談及銷售、利潤和企業發展規劃的公司往往收獲高分,而強調房地產及經營失誤的公司則經常收獲低分🧛🏼🤦🏻♂️。自然語言處理技術可以顯著提高使用者對於模型結果的理解⭐️。

圖3 文本數據比數值數據具有更優越的可解釋性
除了解讀資管模型,文本因子在社會科學中也有廣泛的應用。文本因子結合自然語言處理中前沿的人工智能工具👊🏽,其對應的分析框架在社會科學中也有廣泛應用。例如,之前提及的Cong等(2018)的文章中介紹如何用新聞生成文本因子來預測如GDP增長和失業率等宏觀指標,或是度量創新;又如Cong等(2020)[3]中結合了專業知識和數據驅動的兩種方法,用文本因子生成高維度的公司治理和創新的指標, 不僅彌補了傳統度量單一缺準和無時間序列變化等問題,同時也發現了新的治理維度,並可以應用到公司股東投票結果等的預測中👨🎨。Cong等(2020)[4]中更詳細描述人工智能在社會科學中充滿拓展空間及因子結構如何可以更好開發非結構化數據。
註釋⛹️♀️:
[1] Cong, Tang, Wang, and Zhang, AlphaPortfolio for Investment and Economically Interpretable AI, 2019. Cong, Tang, Wang, and Zhang, Deep Sequence Modeling: Development and Applications in Asset Pricing, 2020.
[2] Cong, Liang, and Xiao, Textual Factors: A Scalable, Interpretable, and Data-driven Approach to Analyzing Unstructured Information, 2018.
[3] Cong, Foroughi, and Malenko, A Textual-Factor Approach to Measuring Corporate Governance, 2020.
[4] Cong, Liang, Yang, and Zhang, Analyzing Textual Information at Scale, 2020.
*本文經原作者授權,僅代表作者個人觀點。